1. 概述
Haystack是facebook开源的储存海量小文件的方案,它是一种针对Facebook的“照片”应用程序优化的对象存储系统,并且对比传统存储系统,Haystack提供了一种更便宜,性能更高的解决方案。
1.1 文件io寻址过程
为了更好的阐述Haystack架构,这里简单回顾一下linux下文件io寻址的过程。
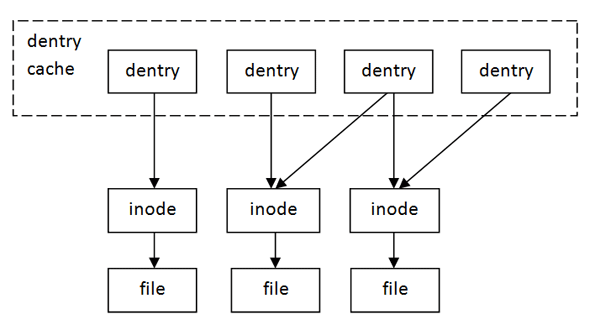
linux里所有文件系统抽象为VFS(虚拟文件系统),每个file结构体都有一个指向dentry结构体的指针, “dentry”是directory entry(目录项)的缩写。我们传给 open、stat等函数的参数的是一个路径,例如/home/akaedu/a,需要根据路径找到文件的inode。为了减少读盘次数,内核缓存了目录的树状结构,称为dentry cache(目录高速缓存),其中每个节点是一个dentry结构体,只要沿着路径各部分的dentry搜索即可,从根目录 /找到home目录,然后找到akaedu目录,然后找到文件a。 dentry cache只保存最近访问过的目录项,如果要找的目录项在cache中没有,就要从磁盘读到内存中。
每个dentry结构体都有一个指针指向inode结构体,inode和dentry是一对多的关系(因此硬链接的存在)。 inode结构体中保存着从磁盘分区的inode读上来信息,例如所有者、文件大小、文件类型和权限位等。inode也有缓存,如果缓存无法命中依然需要从磁盘中读取,在得到inode后便可以访问对应文件的数据。
1.2 为什么
- 元数据过多:假设每个图片文件的metadata占用了100字节的内存,那么260billion(论文中facebook的统计)的图片所占用的metadata便有26000GB之大,但是在训练/对象存储场景下,部分元数据信息(例如权限)是用不到的,因此会浪费大量的存储空间。
- IO开销过大:如1.1所述,在符合POSIX的linux文件系统中,读取一个文件包含:1. 读取dentry,通过文件名关联到inode;2.读取文件的inode信息到内存;3.读取实际的文件内容。如果文件数量太多,内存无法将所有的inode信息缓存,因此对于海量小文件,磁盘的IO次数无法达到只读一次的理想状态,寻址会带来很大的IO开销,这也是Haystack主要解决的问题。
- CDN命中率不高:CDN会依据一些策略移除一些图片缓存,但是在facebook的社交场景中,long tail(指用户访问不热门的图片导致CDN缓存无法命中)频繁出现,提升命中率需要大量的开销。
1.3 传统方案
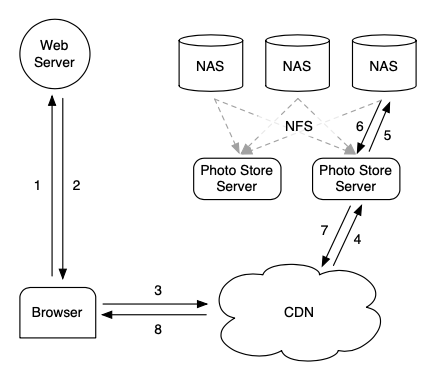
在Facebook的传统架构里,图片的缓存用CDN实现,底层使用基于NAS的商业存储方案,Photo Store Server通过NFS挂载NAS中的图片文件提供服务,用户的图片请求首先调度到最近的CDN节点,如果节点没有命中CDN会请求后段的存储系统,缓存图片并返回给用户。
但如同1.1中的第三点所述,社交场景存在大量的long tail,根据论文中Facebook的统计数据,非用户头像的图片命中率只有约92%;同时,这个架构也没有解决海量图片文件的IO问题,海量的小文件让缓存所有的inode信息变得不可能,因此每次文件的读取需要约3次IO操作;最后,Facebook的CDN依赖于外部提供商,也让不可控因素变得更多。
2. 原理
基于上述的原因,Facebook设计了Haystack架构。
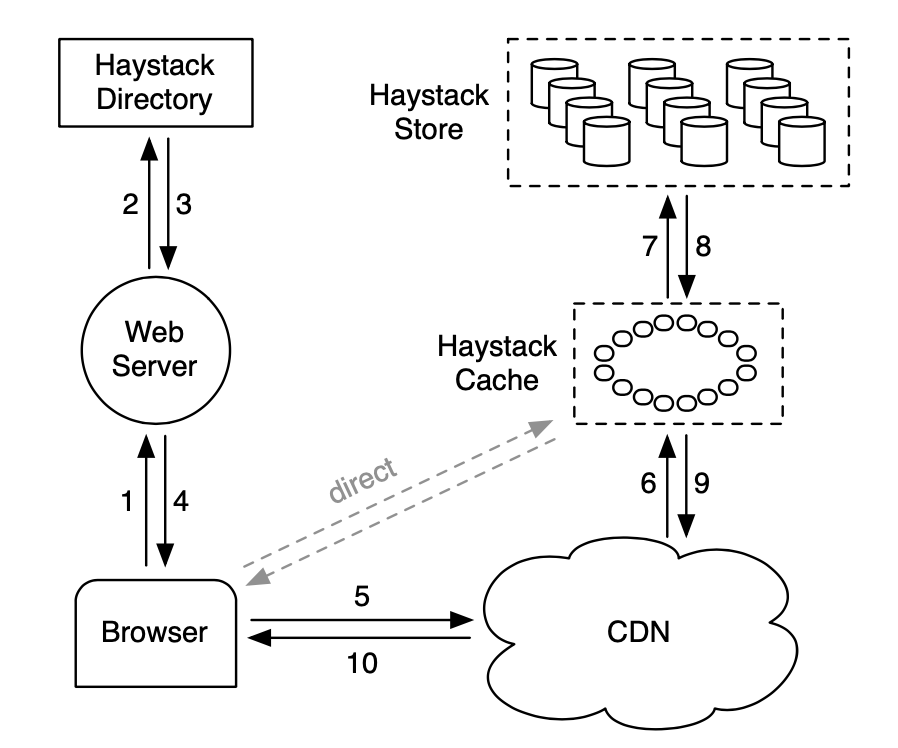
Haystack架构主要由Directory,Cache和Store三个模块组成。
2.1 术语
FID:图片文件的唯一标识符,格式为<Volume Machine, Offset, Size>
物理卷(Physical Volume):store组织存储空间的形式,例如在10TB的存储节点上会分出100个100GB的物理卷。
逻辑卷(Logical Volume):多个不同节点上的物理卷共同组成一个逻辑卷,用于实现备份的功能
Store:提供图片文件持久化存储的模块,以物理卷(physical volume)的形式组织存储空间
Directory:类似metadata server,负责生成文件fid,用于记录逻辑卷和物理卷的映射关系,维护逻辑卷的read-only属性,并决定请求 直接走CDN还是haystack cache server
Cache:类似内部CDN
Needle:物理卷内,每个图片文件的存储形式
2.2 Directory
Directory有四个功能:
- 提供逻辑卷到物理卷的映射关系,web server需要通过它构建上传或访问图片的url
- 均衡读写请求的负载
- 决定请求是否通过CDN
- 维护逻辑卷的只读属性(处于压缩中或没有多余空间的逻辑卷)
2.3 Cache
Cache只有同时满足以下两种情况才会缓存图片:
- 请求直接从用户发送而不是CDN
-
图片从可以写入的Store节点中读取
根据论文中的统计,对于CDN无法命中的缓存再加一个二级缓存是没有意义的;而刚上传的图片是更容易被读取的,因此对于可写入的节点添加一层缓存以确保它的写入性能。
2.4 Store
2.4.1 Haystack Store File
Store本质是把多个小文件合并成一个大文件以减少IO,Store节点在收到请求后可以根据逻辑卷id和文件offset快速到大文件内的图片信息。Haystack的关键便是不通过磁盘操作得到文件的名称、offset和size信息,Haystack Store内的文件格式如下图。
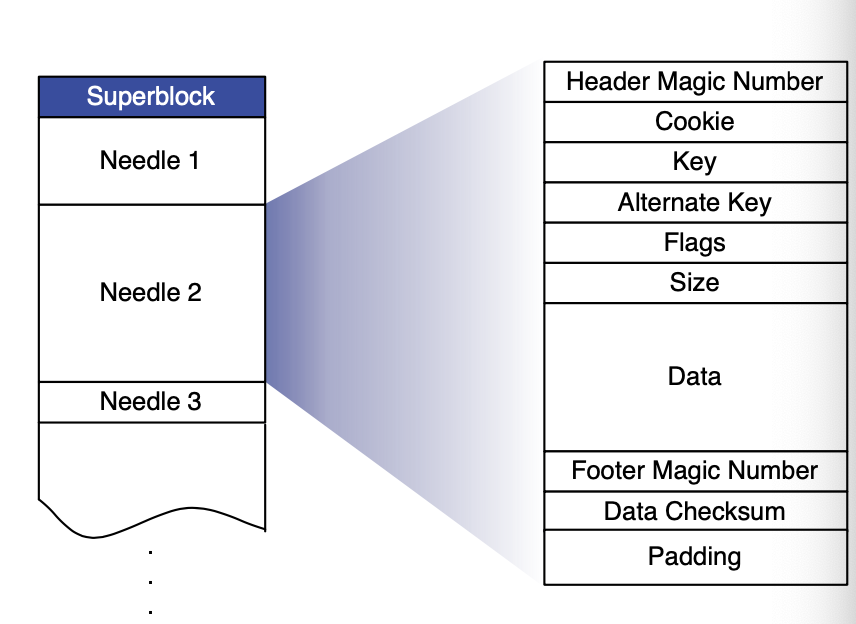

Store内的文件以Needle的形式存储,同时删除操作是通过修改Needle的flag字段实现的。
一个物理卷其实就是一个大文件,这个大文件由一个Superblock和数个Needle构成,每个Needle相当于一个图片文件,Needle各个字段的含义如上图所示。
2.4.2 Haystack Index File
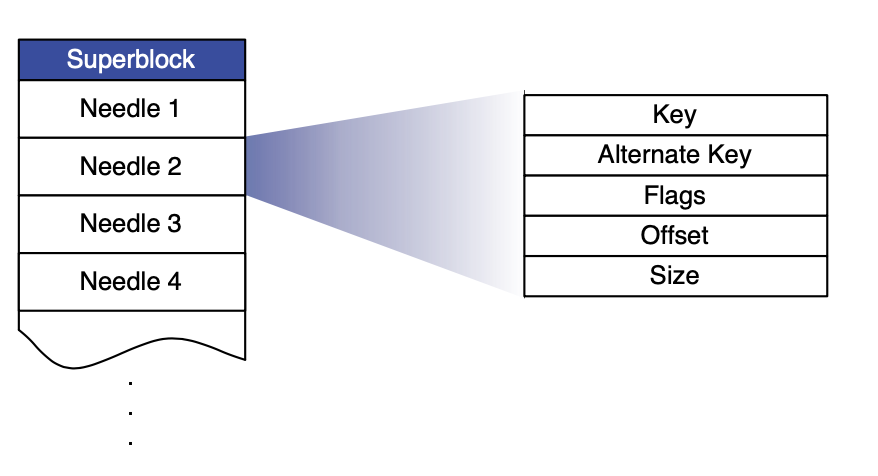
为了快速从物理卷中读取到对应的图片文件,Store节点的内存会为每个物理卷维护一份索引文件,这份索引会将Needle的Key和Alternate Key映射到它的Flag,Size和Offset。在节点故障重启时,Store节点可以读取Index File实现快速恢复,读取Index File的IO开销将比直接读取Store File小得多
- 读:请求一个图片时,url内会有Volume id,Key,Alternate Key,Cookie信息,Cookie是一个随机生成的数字,用于防止猜测图片url有效的攻击。Store收到请求后会从物理卷内读出Needle,如果Needle的Flag显示文件没有被删除,且Cookie校验通过,图片文件便会被返回。
- 写:Store的写本质就是append操作。上传一个图片会将图片信息写入到逻辑卷映射的所有物理卷内以实现备份,注意Haystack不允许覆盖写,对图片的更新操作都会通过更新Directory的信息实现,旧的图片并不会直接删除。如果有重复的Needle,Store会返回Offset最大的文件。
-
删:删除直接更新Needle内的Flag字段,Store会定期对物理卷进行压缩操作删除这些文件。
Index File相当于索引文件的checkpoint,文件的写入和删除都是并行的,这会带来Index File和Store File不一致的情况,Haystack是通过下面两个操作解决的:
- 孤儿文件:在重启时,Store会对没有索引的Needle重新创建一个索引,并将索引append到Index File的末尾
- 索引文件未标记删除:文件在被读取时会校验Flag更新索引内的Flag
2.4.3 优化
-
Store会定期对Store File进行压缩操作,该操作会修改该逻辑卷为不可写入,同时整个的复制Store File,如果遇到标记删除的文件那么直接跳过。这个操作往往会持续数小时。
-
Index File在内存中的Cookie字段可以节省。
2.5 总结
Haystack通过把小文件转化为大文件的方法避免了磁盘的多次IO,从而优化随机小文件读取的性能。这种方法适用于多读少写的情况,因为每次写操作实际为一次append,过多的修改会造成大量的存储空间浪费,而每次回收逻辑卷的操作会持续数小时,因此这种策略并不适合多写入的情况。
3. Seaweedfs
Seaweedfs是Haystack的Go语言实现,这里作为扩展简单的介绍一下Seaweedfs。repo地址:https://github.com/chrislusf/seaweedfs
核心模块
- Storage:实现Haystack中Store、Volume和Needle,其中抽象出了Index File的存储接口,使其能对接自定义的存储后端(源码实现了leveldb,内存和mysql)
- Topology:拓扑结构,包含DataCenter,Rack,DataNode,由Master Server维护,DataNode负责存储Volume内的相关信息,拓扑结构为DataCenter -> Rack -> DataNode
1
2
3
4
5
6
7
8
9
10
11
12
13
DataCenter
|
|
------------------
| |
| |
Rack Rack
|
|
------------
| |
| |
DataNode DataNode
- Weed Server:以Go的Raft库实现一致性的master节点,负责Seaweedfs的入口
- Filer:实现Haystack内的Directory,元信息数据库,并且抽象接口,对接自定义存储后端(源码实现了mysql,etcd,leveldb等)
- Stats:通过Prometheus上报各项性能指标
Filer Store
Filer Store被抽象为以下接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
type FilerStore interface {
// GetName gets the name to locate the configuration in filer.toml file
GetName() string
// Initialize initializes the file store
Initialize(configuration util.Configuration, prefix string) error
InsertEntry(context.Context, *Entry) error
UpdateEntry(context.Context, *Entry) (err error)
// err == filer_pb.ErrNotFound if not found
FindEntry(context.Context, util.FullPath) (entry *Entry, err error)
DeleteEntry(context.Context, util.FullPath) (err error)
DeleteFolderChildren(context.Context, util.FullPath) (err error)
ListDirectoryEntries(ctx context.Context, dirPath util.FullPath, startFileName string, includeStartFile bool, limit int) ([]*Entry, error)
ListDirectoryPrefixedEntries(ctx context.Context, dirPath util.FullPath, startFileName string, includeStartFile bool, limit int, prefix string) ([]*Entry, error)
BeginTransaction(ctx context.Context) (context.Context, error)
CommitTransaction(ctx context.Context) error
RollbackTransaction(ctx context.Context) error
KvPut(ctx context.Context, key []byte, value []byte) (err error)
KvGet(ctx context.Context, key []byte) (value []byte, err error)
KvDelete(ctx context.Context, key []byte) (err error)
Shutdown()
}
其中Entry定义如下,它是文件的元数据:
1
2
3
4
5
6
7
8
9
10
11
12
type Entry struct {
util.FullPath
Attr
Extended map[string][]byte
// the following is for files
Chunks []*filer_pb.FileChunk `json:"chunks,omitempty"`
HardLinkId HardLinkId
HardLinkCounter int32
}
Filer的工作流程如下:
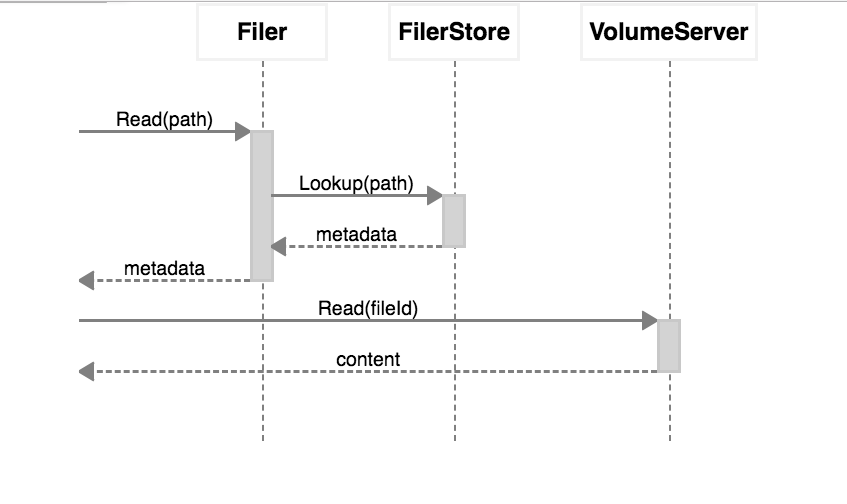
Store
Seaweedfs对Volume,Superblock和Needle的定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
type Volume struct {
Id VolumeId
dir string
Collection string
dataFile *os.File
nm NeedleMapper
readOnly bool
SuperBlock
accessLock sync.Mutex
lastModifiedTime uint64 //unix time in seconds
}
/*
* Super block currently has 8 bytes allocated for each volume.
* Byte 0: version, 1 or 2
* Byte 1: Replica Placement strategy, 000, 001, 002, 010, etc
* Byte 2 and byte 3: Time to live. See TTL for definition
* Rest bytes: Reserved
*/
type SuperBlock struct {
version Version
ReplicaPlacement *ReplicaPlacement
Ttl *TTL
}
/*
* A Needle means a uploaded and stored file.
* Needle file size is limited to 4GB for now.
*/
type Needle struct {
Cookie uint32 `comment:"random number to mitigate brute force lookups"`
Id uint64 `comment:"needle id"`
Size uint32 `comment:"sum of DataSize,Data,NameSize,Name,MimeSize,Mime"`
Data []byte `comment:"The actual file data"`
DataSize uint32 `comment:"Data size"` //version2
Flags byte `comment:"boolean flags"` //version2
NameSize uint8 //version2
Name []byte `comment:"maximum 256 characters"` //version2
MimeSize uint8 //version2
Mime []byte `comment:"maximum 256 characters"` //version2
LastModified uint64 //only store LastModifiedBytesLength bytes, which is 5 bytes to disk
Ttl *TTL
Checksum CRC `comment:"CRC32 to check integrity"`
Padding []byte `comment:"Aligned to 8 bytes"`
}
文件的FID格式为<VolumeId, NeedleId, Cookie>,例如"fid":"1,01f96b93eb"就是一个fid,逗号前面的是VolumeId,NeedleId和Cookie的意义已经在Haystack内容解释过了。
Superblock结构体内的ReplicaPlacement实现了Seaweedfs的备份,Seaweedfs支持如下的备份模式,其中Topology模块会负责生成全局的唯一VolumeId,其全局一致性通过master节点的GoRaft实现。
1
2
3
4
5
6
7
8
9
+-----+---------------------------------------------------------------------------+
|001 |replicate once on the same rack |
+-----+---------------------------------------------------------------------------+
|010 |replicate once on a different rack in the same data center |
+-----+---------------------------------------------------------------------------+
|100 |replicate once on a different data center |
+-----+---------------------------------------------------------------------------+
|200 |replicate twice on two other different data center |
+-----+---------------------------------------------------------------------------+
Seaweedfs实现了强一致性,如果上传的文件需要备份,那么会在文件备份完成后再返回上传结果,同时,Master Server会维护每个VolumeId的备份列表。
Superblock内的TTL用于实现定时删除,每个上传文件会自带TTL,同时volume也会维护一个最大TTL,一旦到达,Master Server便不会对这个Volume分配FID,在一段时间后便会将这个Volume从磁盘内删除。
总结
Seaweedfs是开源的Haystack实现,除了Haystack的基本功能外,它还支持配置节点的扩容和备份策略等,同时底层的存储引擎也开放用户自己定制;同时,它除了支持http restful API接口外,也支持通过fuse挂载到用户本地盘。阅读Seaweedfs的代码也能学到很多Golang编程的规范,这里也推荐大家有空可以读一读存储引擎接口的实现。
Seaweedfs的更多操作可以详见官方wiki:https://github.com/chrislusf/seaweedfs/wiki/Getting-Started