为什么我要写这个?
记录一下本人从算法出身到从事工程再”从零开始“利用网络的文档学习LLM算法的过程
网上关于大模型算法的论文解读,深入理解等文章已经够多了,因此本篇文章不会写太多解读相关内容,我更希望这篇文章是一个索引或者指南,把所有值得学习的文档(包括论文)整理起来,通过按照顺序阅读这些文档循序渐进的学习大模型的相关知识
本文会以你没有大模型相关知识为开头,从机器学习基本原理开始逐步介绍NLP的范式,最终以InstructGPT为结尾
如何学习?
就本人经验来说,如果想定量的学习NLP和LLM相关知识,建议用深度递归学习法,在看文档时只要遇到不懂的概念立即去关键词搜索+学习了解,在学习时先定性的去知道一个概念是什么,了解该概念的提出是为了解决什么问题,然后再定量的知道原理。举个例子,如果你不知道机器学习最基本的神经元,那么首先你需要定性地了解神经元是什么(神经网络的最小单元),了解提出这个东西是为了解决什么问题(为了模拟人脑神经元之间的相互作用),然后再定量的去了解神经元的原理(输入输出和激活函数)
如果想定性的学习,现在网络上已经有很多介绍GPT原理的视频,随便抽一个看即可。
一些必要的前置知识
统计学,概率论
线性代数(矩阵计算那一块)
离散数学的基本知识(各种符号,极限,级数等得看得懂)
机器学习基本概念
这个就很简单了,随便一搜就是一堆文章,先系统性的对机器学习有个大概得认知就可以了,本节你需要了解:
- 基本模型有啥,是干什么的
- 各个模型为了解决什么东西
- 机器学习的训练测试验证集合是什么,怎么用的
- 机器学习的输入是什么?输出是什么?
- 模型训练是在干什么事?
- 为什么机器学习是在”训练“模型
- 什么是欠拟合和过拟合
- 机器学习的训练目标是什么
- 监督无监督和强化是什么
学习这些不用去定量了解,知道这些概念是干啥的就行,如果从这里开始定量了解那基本就停不下来了
这里随便推一篇
我会怎么展开接下来的内容
在了解完机器学习的基本概念之后,你大概也会对机器学习的一些点有了认知(如果以下的点你不了解,也需要去定性地学习下),由于本文只涉及LLM相关,因此接下来的内容也将从nlp的这些点切入:
预处理(preprocess) -> 分词(Tokenization) -> 模型优化(optimization) -> 模型(会拿transformer举例) -> 精调(fine tuning)
那么,接下来咱们从机器学习的整个流程开始逐个切入他们的原理
预处理(preprocess)
机器学习极其依赖数据的质量,因此在训练前数据的预处理永远都是最关键的一步,本节你需要了解:
- 预处理做了什么?
- C4、CommonCrawl等开源数据源是什么,如果有条件可以下载一些浏览看看
- 这些数据是如何应用到模型的训练中的
需要去看的文档
分词(Tokenization)
分词,简而言之就是把一句话分成多个词组,例如我是一个人类,我喜欢水果可以被分词为["我", "是", "一个", "人类,", "我", "喜欢", "水果"]。
由于机器是无法直接理解人类语言的,因此人类语言首先要被转化为机器可以理解的向量(这个向量维度越高,所包含的信息也就越多),而在自然语言,词是最小的单位,如果直接把一整句话转化为向量便会丢失大量的信息,所以我们需要首先把句子拆分为词组,然后再对每个词转化为向量,最后将一句话的所有向量拼接成矩阵(例如一个句子分词后有N个词,每个词的向量维度为M,那么就可以组成一个N*M的矩阵)
本结你需要了解:
- 分词干了什么事?
- 为什么需要把句子分词?
- bpe、wordpiece和unigram language model这三种分词模型的原理是什么?
- 什么是词嵌入
- 如何解决不同长度句子的转化为矩阵后的维度不一致的问题?
需要去看的文档:
模型优化(optimization)
我把模型优化放到了模型前面,因为本章将会引入机器学习一个重要的概念——梯度下降,它是机器学习训练的核心,并且会以梯度下降为核心展开模型优化算法内的学习率和损失函数等概念
梯度下降
我们知道,机器学习本质是将一个输入的$M * N_1$矩阵通过计算转化为另一个$M * N_2$的输出矩阵,而模型内的所有参数都是以矩阵的形式存在的,模型训练即用训练集的输入输出去逐步地优化模型参数,让模型在训练集上的输出更加贴近实际输出(比如线性回归就是一个梯度下降优化的过程)。
本节你需要了解:
- 什么是梯度下降
- 梯度下降是如何计算的
- 手推一下梯度下降的公式
学习率
上一节我们知道了最简单的BGD和SGD,但是在实际场景中我们经常会遇到鞍点问题,而传统的基于固定学习率的梯度下降算法无法有效的解决鞍点,因此在大模型的训练里我们会用到更多看起来很花哨的梯度下降算法
本节你需要了解:
- 鞍点是什么,如何解决训练中的鞍点问题
- 定量了解momentum、adagrad、adam优化算法的原理
损失函数
模型训练时,我们需要一个函数去评估模型的输出和实际输出的损失有多大(也可以理解为误差有多大)
需要看的文档: 损失函数是什么,代码里如何编写,交叉熵损失函数,最大似然估计
本节需要了解:
- 损失函数是什么,最好代码层面实现一下
- 交叉熵损失函数和最大似然函数是什么,解决了什么问题
- 定量了解交叉熵损失函数和最大似然函数的推导
- 交叉熵函数和最大似然函数的区别是什么
正则化
正则化就是避免模型训练中的过拟合现象,通过引入噪音,清洗数据集的方法让模型的训练更不容易出现问题
本节需要了解:
- 正则化是什么,有什么作用
- 尝试用代码写正则化
激活函数
为什么需要在单个神经元的输出经过激活函数:1. 解决线性不可分问题;2. 避免梯度消失和梯度爆炸;3. 归一化
具体文档可查看这篇
本节需要了解:
- 激活函数常见的有哪些
- 定量了解为什么需要激活函数
模型
Transformer
transformer架构可以说是一切llm的根源
这里强烈推荐把transformer论文全篇阅读,第一次阅读能对模型有一个定性地认知即可
读完论文后你肯定有很多不解的地方,可以直接搭配中文详解再精度一遍,对论文的讨论有定量的认知,如果觉得不够还可以看这个,如何写代码可以参考这个,BERT和transformer的区别可以参考这个回答
然后再读这个了解为什么transformer模型是这个形态,即回答为什么用论文中的方案能很好的解决transformer模型所面对的问题
本节需要了解:
- transformer原始论文中用到了什么embedding?为什么transformer模型架构需要引入额外的位置编码?论文中如何生成词语位置编码?
- transformer论文中如何解决变长输入?
- transformer的模型架构是什么样的(能在脑子里立即想出来)
- 什么是self attention?具体的公式是什么样的?
- 为什么需要将原始输入$X$转化为$Q,K,V$三个矩阵计算?直接将$K$和$Q$使用同一个权重矩阵生成行不行?为什么self-attention公式内的softmax需要除以$\sqrt{d_k}$
- 什么是multi head attention?为什么需要multi head attention?为什么multi head attention要降维?
- attention mask是什么?有什么作用?
- transformer论文中的encoder和decoder有什么区别?
- 以翻译为场景思考下encoder层的输出如何进入decoder层内进行误差计算
- 为什么transformer论文中使用batch norm做归一化而不是layer norm
BERT
本节需要把BERT论文定性阅读,相比transformer,BERT引入了pretrain+fine tuning的训练模式,同时也只使用了transformer的encoder部分,为后续的llm训练范式打下了基础
定性读完后可以结合中文详解定量了解BERT,然后再阅读这篇学习为什么选择用BERT和预训练+精调来解决NLP的问题
本节需要了解:
- BERT的模型架构是什么?和GPT(注意这里可不是openai那个GPT,而是最初的GPT模型)有什么不同?和transformer比起来有什么不同?
- BERT论文中用到了什么embedding?
- BERT论文中的位置编码和transformer有什么不同?
- pretrain是如何做到的?训练集长什么样?为什么说是无监督训练?
- 为什么激活函数从ReLU换成了GELU(定性了解即可)
- fine-tuning是如何在pretrain后的模型上做到的?
- BERT在哪些任务上有更好的表现?
其实BERT是transformer之后在nlp领域被广泛推崇的模型,后来出现了很多基于bert的模型(如ALBERT等),不过由于原理相似,读者可以自行了解,这里不再展开
T5
老样子,T5论文先看看,这篇论文其实也没有太多定量的内容,其内容就是大型Seq2Seq的BERT+干净的数据+多任务+一些改动的整理,论文的作者深入对比了不同的预训练目标、模型结构、无监督数据集、迁移方法、NLU任务,最终拼成了T5。你可以简单理解为在transformer基础上做了大量的模型参数时延最终得到了一个结论,而基于这个结论搭建的模型就叫T5
T5论文将所有NLP问题归结为了text-to-text任务,并引出了训练数据对训练结果的影响(论文中的C4数据集),然后通过大量实验得出预训练的目标(如mask掉多少,mask平均长度为多少),最终得到了一系列基于transformer的结论,简单来说就是个实验报告,详细可以看中文详解
T5用到的位置编码可以看这篇论文
本节需要了解:
- 各个NLP领域的问题是如何在T5论文中被转化为text-to-text任务的?
- T5做了哪些实验?得到了哪些结论?
- 论文中的T5参数量有多大?
- T5用到的relative position embeddings是什么原理?
GPT
请注意,这里的GPT并不是指openai的那个GPT产品,而是最早的Generative Pre-Training模型。其实当T5问世的时候,很多人认为t5就是nlp领域的最终解,后续要做的无非是优化训练集加大参数量罢了。但是现在我们都知道,gpt的异军突起直接把t5干趴下了,这也是我把GPT放到T5之后介绍的理由,即使GPT模型本身是早于T5的
GPT架构选择了transformer内的decoder,因此训练时不会关注后向词语的关注度信息,其pretrain的训练目标是极大化词语序列的似然估计,fine-tuning就是极大化精调层的目标函数,如果你弄懂了transformer和BERT的话,GPT原理其实十分简单
本节需要了解:
- GPT的模型架构和BERT有什么区别?和transformer有什么区别?
- GPT论文中的模型参数量是多少?
- GPT是如何完成预训练和精调的?
GPT-2
GPT论文中提到在zero-shot的设定下,模型的表现能力与解码器层的数量呈正相关,因此我们看到GPT-2相比GPT而言,transformer层翻了4倍(48层),因此参数量也变为了1.5B(1542M)。同时GPT-2的训练用到了自行清洗的WebText的数据集(可以看出后续的LLM训练对数据集的要求都很高),该数据集从Reddit上收集了至少有3个赞的外部链接文本,覆盖领域十分广阔,GPT-2论文中指出规模大的模型必须要用更多的数据才能收敛,最终的实验结果也表明GPT-2的模型仍然处于一个欠拟合的情况。架构方面,GPT-2依然使用Decoder,并做出了一些细节上的修改(前置层归一化和后置层归一化)。GPT-2的目标是证明有一种模型完全不需要对下游任务进行适配就可以表现优异,因此论文作者从WebText数据集中清洗出各个NLP任务的训练数据(问答、翻译等),实验结果也证明GPT-2的泛化能力十分强大,在8/9个NLP任务里都达到了当时的SOTA
GPT-2引出了zero-shot learning的概念,可以简单理解为不提供答案上下文的情况下询问llm问题,如把中文翻译成英文: 我 => ?是zero-shot,把中文翻译成英文: 你 => you, 我 => ?是one-shot。当然,受限于参数规模,GPT-2本身在one-shot和few-shot的表现上也不尽人意
本节需要了解:
- 什么是zero-shot,什么是one-shot
- GPT-2和GPT在模型架构上有什么不同
- GPT-2用到了什么分词方法
- GPT-2在zero-shot和one-shot上的表现如何?
GPT-3
先看GPT-3的论文,然后中文翻译版,到这里也可以读一下GPT系列的总结
GPT-3延续了GPT-2的大力出奇迹思路,直接把模型的参数量提升到了175B(对比GPT的0.15B和GPT-2的1.5B),并且继续探索了不对下游任务进行适配时模型的表现(即依然不做任何fine-tuning)。不同于GPT-2的zero-shot,GPT-3旨在探索大模型的In Context Learning能力,即根据问题上下文进行学习并给出解答的能力,就是我们之前提到的few-shot,而GPT-3的评估也用到了zero-shot、one-shot和few-shot三种条件进行,结果也显示模型越大,上下文学习学习能力就越强
GPT-3的预训练方法和GPT-2类似,不过GPT-3扩大了模型的大小(显而易见的,毕竟从1.5B到了175B)、数据集大小和多样性以及训练文本长度,同时也设置了四种不同上下文的few-shot模板来精调,从论文的量化评估来看GPT-3也确实做到了对其他模型的降维打击
总结一下,从GPT到GPT-3我们可以发现,OpenAI选择了和Google完全不同的道路,当Google在深度探索pretrain+fine-tuning解决单一场景问题时,OpenAI则是在大力出奇迹(只用pretrain覆盖所有NLP场景)的道路上越走越远,直到GPT-3的问世终结了这一竞争
本节需要了解:
- GPT-3是如何训练的?
- GPT-3和GPT-2有何不同?
Parameter-Efficient Fine-Tuning & Prompt Tuning
GPT-3之后,大模型的概念逐渐明朗(也很好理解,毕竟GPT-3都有了175B的参数量了),但是很明显,此时的显卡并不能很好的装载这些大模型,以FP16半精度格式计算,一个175B的GPT-3模型都需要320GB存储空间了,而训练时的梯度数据则更是会成倍的增加显存的占用,这将导致模型的训练时间变得恐怖,以前一天就能训练好的模型现在则需要数月,而且单个任务的全参数微调也容易造成通用性的损失,容易使模型陷入过拟合中
为了解决上述问题,从GPT-2开始,一种新的思维被提出:与其全参微调模型,不如固定模型大部分参数,在Transformer层中添加额外的参数,并只微调这一小部分来达到Fine Tuning的效果,这种范式我们称之为PEFT(Parameter-Efficient Fine-Tuning),其主要有Adapter Tuning和LoRA等。不过随着Prefix Tuning和P-Tuning等被提出,一个更加有意思的命题也诞生了——Prompt Tuning。
不同于PEFT在Transformer层添加额外参数训练,Prompt Tuning似乎更加喜欢修改输入序列的embedding,类似于在把输入语句嵌入一个模板一样。Prompt Tuning也被分为Discret Template(可以理解为添加离散的token序列)和Continuous Template(可以理解为生成连续的embedding),其中比较关键的几种方案有Soft Prompt Tuning, Prefix Tuning,P-Tuning和P-Tuning V2,它们的异同我将在本章最后展开
Adapter Tuning
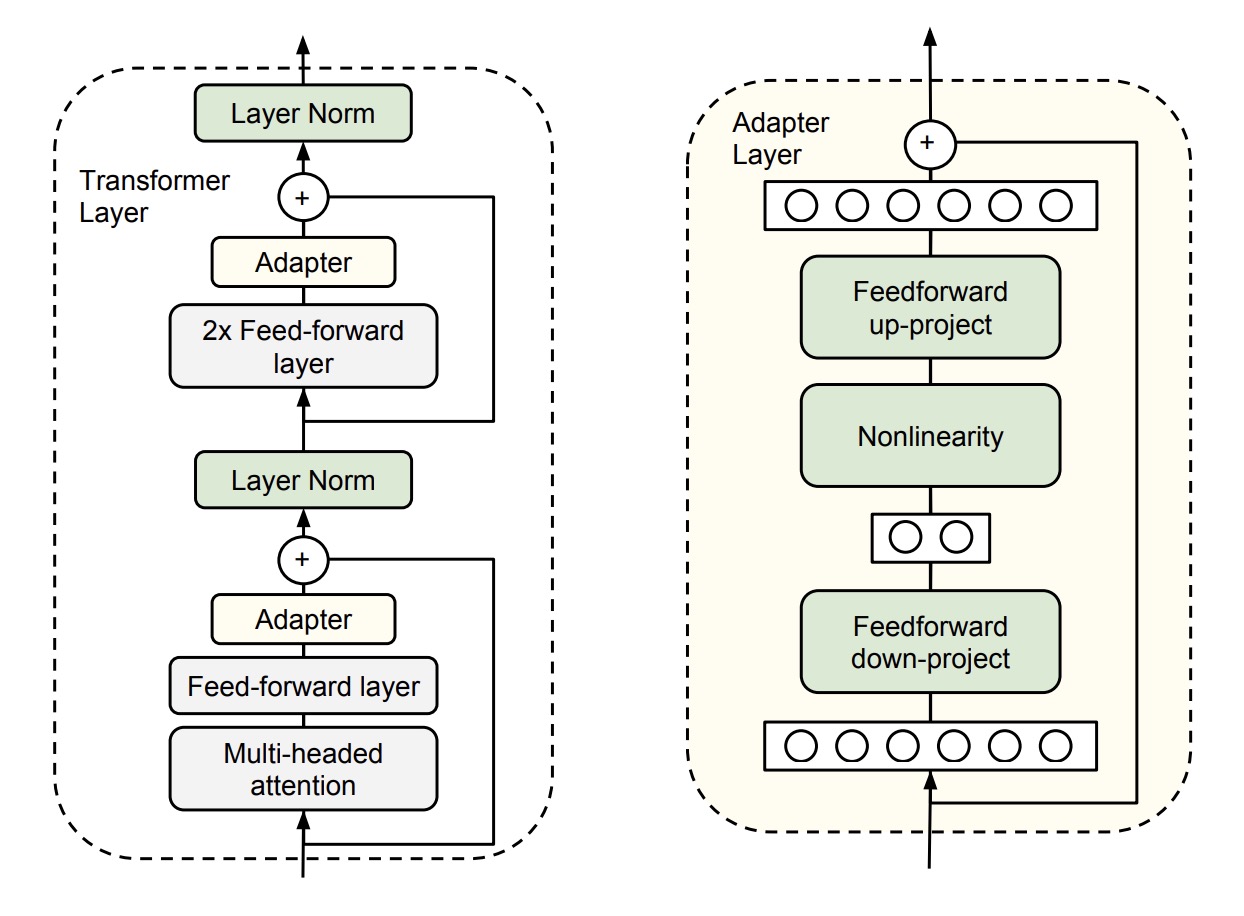
adapter tuning就不用看论文了,其原理一张图就能看懂。精调时,在预训练好的transformer模型中的每个前向传播层后添加一个adapter layer,该层会对输入进行一次降维和升维操作,并且为了防止最差的情况也设计了skip-connection结构(可以直接identity)
该方法最终用3.6%的参数量获得了和精调差距在0.4%以内的效果,并且收敛速度也大幅度增加
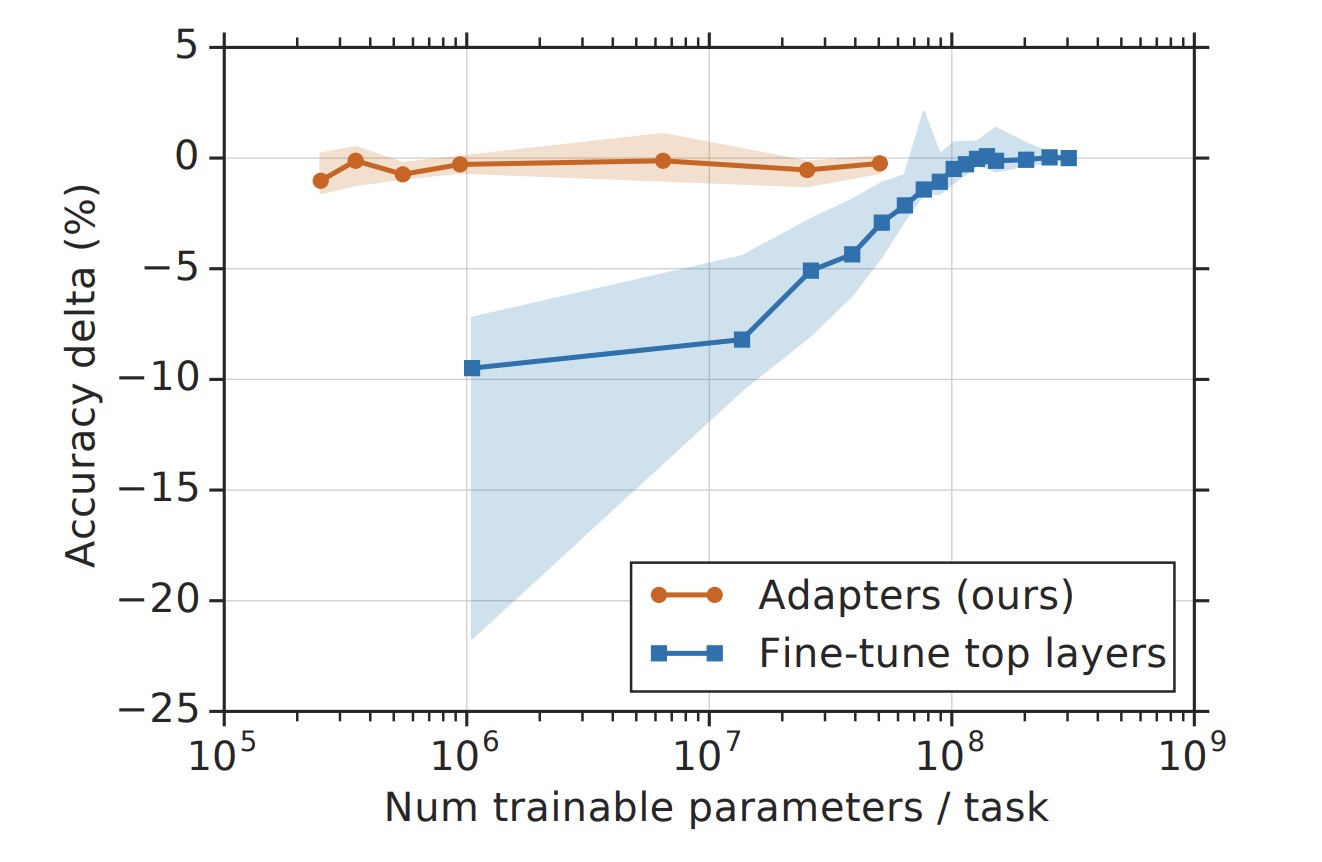
Adapter Tuning其实和后来的Prompt Tuning没有太多关系,它主要证明了对于Transformer架构的模型,通过固定模型参数+添加部分可训练参数的精调模式是可行的,为后来的Prompt Tuning打下了基础
本节需要了解:
- 定性了解Adapter Tuning的原理
LoRA
LoRA其实和Adapter Tuning类似,是一种低资源量微调大模型的方法,它的原理其实很简单,给Multi Head Attention内的$W_Q, W_K, W_V$矩阵添加一个低维0映射+MLP+高维映射来更新参数,这些低秩分解的输出最终会和矩阵输出求和,然后精调时冻结模型只更新这些低秩参数,和Adapter Tuning比起来,由于它的参数计算是并行,所以它并不影响模型的推理速度,换句话说,精调速度很快
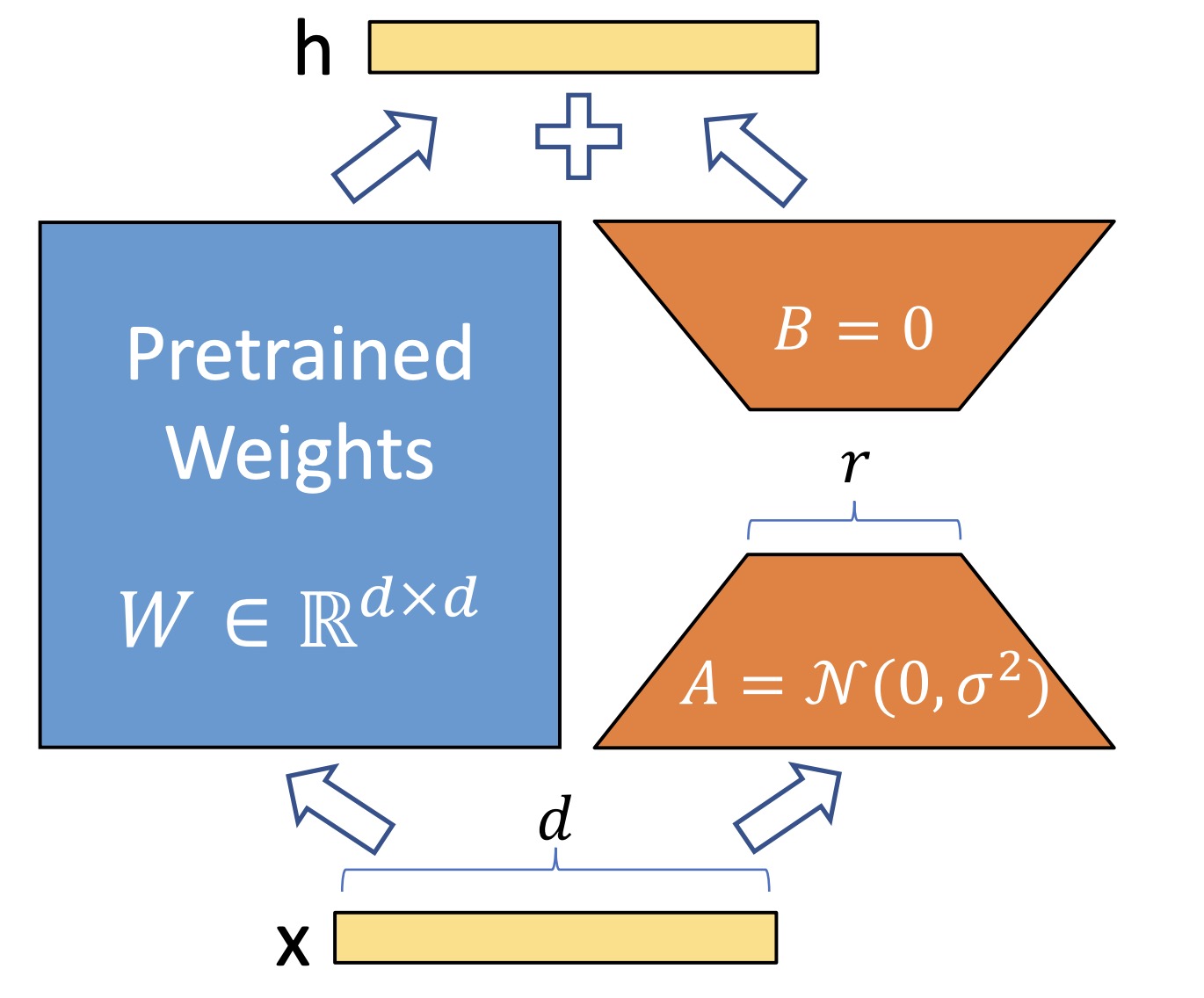
和Adapter Tuning一样,这个东西不太需要定量了解,只需要知道它证明了大模型内在秩和小参数量更新是有效的即可,如果你要定量了解原理的话可能你还得去复习下线代里矩阵秩的相关知识
本节需要了解:
- 定性了解LoRA的原理
Pattern-Exploiting Training
PET(Pattern-Exploiting Training)可以简单理解为人工构建模板,即Discrete Template,这种构建出来的模板称为Hard Prompt,该方法将情感分类等NLU任务通过完型填空的模板变为NLG任务,它通过在输入中嵌入人工固定的语句来增加大模型在某类任务上的评估指标。举个例子,现在有感情分类任务I love this movie.,为了让这个输入更贴近预训练的预料,我们可以将其改为完型填空的格式I love this movie. The movie is <MASK>,然后让模型预测下一个词(即这句话的情感分类结果),如此便将NLU任务变为了NLG任务
这种手动构造prompt的模式有一定的局限性,因为离散化寻找出的结果可能不是最优,而且对token的变动十分敏感,所以后续的研究大多都是基于Continuous Prompt进行,相关的论文感兴趣可以看一看
本节你需要了解:
- PET是如何把NLU任务转化为NLG任务的?
Soft Prompt Tuning
Soft Prompt Tuning的原理很简单,从清华给出的代码里就可以理解。在tuning阶段冻结模型的参数,然后将输入文本的embedding的输入序列左侧拼接一个soft embedding作为最终的输入embedding传递给Multi Head Attention层(注意这里的Soft Prompt也是占用input seq length一部分的),tuning阶段的目标便是训练这个soft embedding,所以这种PEFT的方法又称为Soft Prompt,其原理如下图所示:
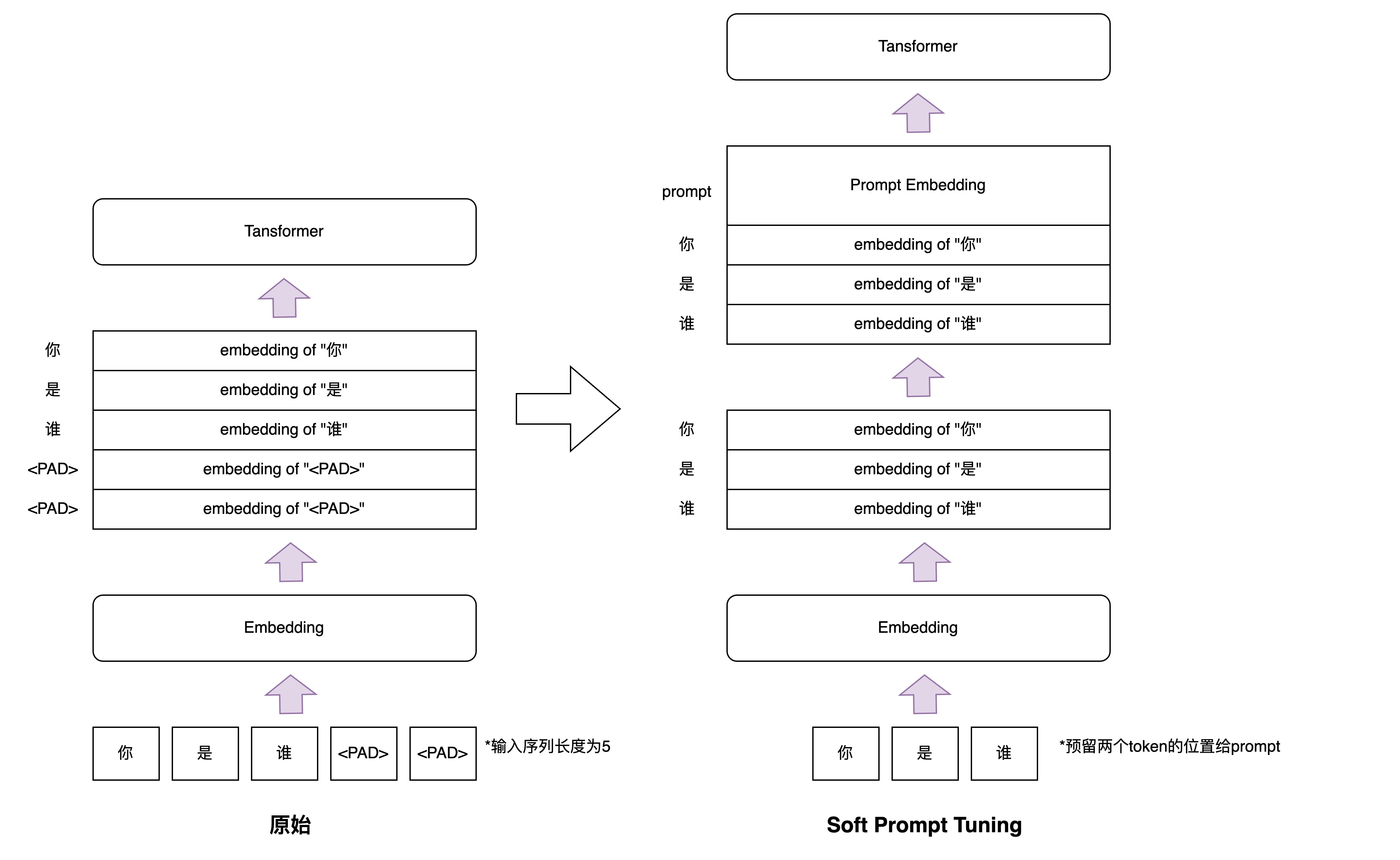
Soft Prompt Tuning是一种Continuous Template,针对的模型是T5等MLM的NLG任务,但很明显这种prompt不具备通用性,每种下游任务只能精调一种,而且作为早期的Prompt Tuning方法,和后面的Tuning方法比起来,其评测指标已经没有了参考价值
本节需要了解:
- Prompt Tuning的原理,看懂代码实现
- Prompt Tuning是如何修改embedding的
Prefix Tuning
先附上论文和中文翻译,看完后可以再看看这个里的prefix-tuning部分和实现代码
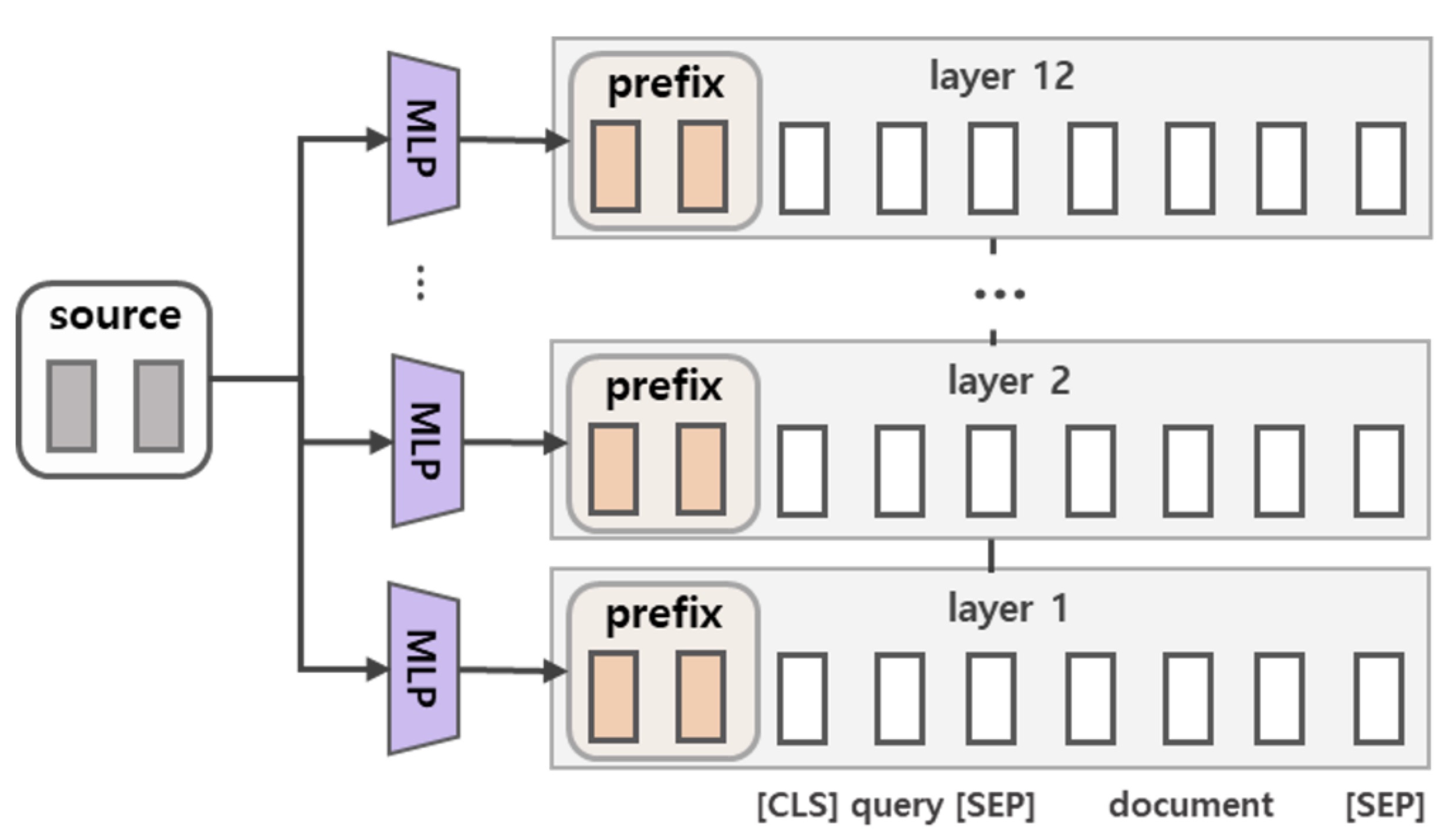
Prefix Tuning你可以理解为给每个Transformer层的输出都加了不同的Soft Prefix(注意Soft Prefix是不占用seq length的),tuning时只更新这些Soft Prefix的参数。不过在具体实现上,为了防止直接更新Prefix的参数导致训练不稳定和性能下降,论文作者在Prefix层前面添加了一个MLP结构(每层都保留一个),通过一个小维度embedding和每层的MLP生成每层的Soft Prefix Embedding,增加了可训练的参数量,在训练结束后模型只保留MLP生成后的Prefix Embedding。其具体到某个Multi Head Attention层计算的原理如下图所示(注意里面忽略了softmax等操作,只关注矩阵的dim变化):
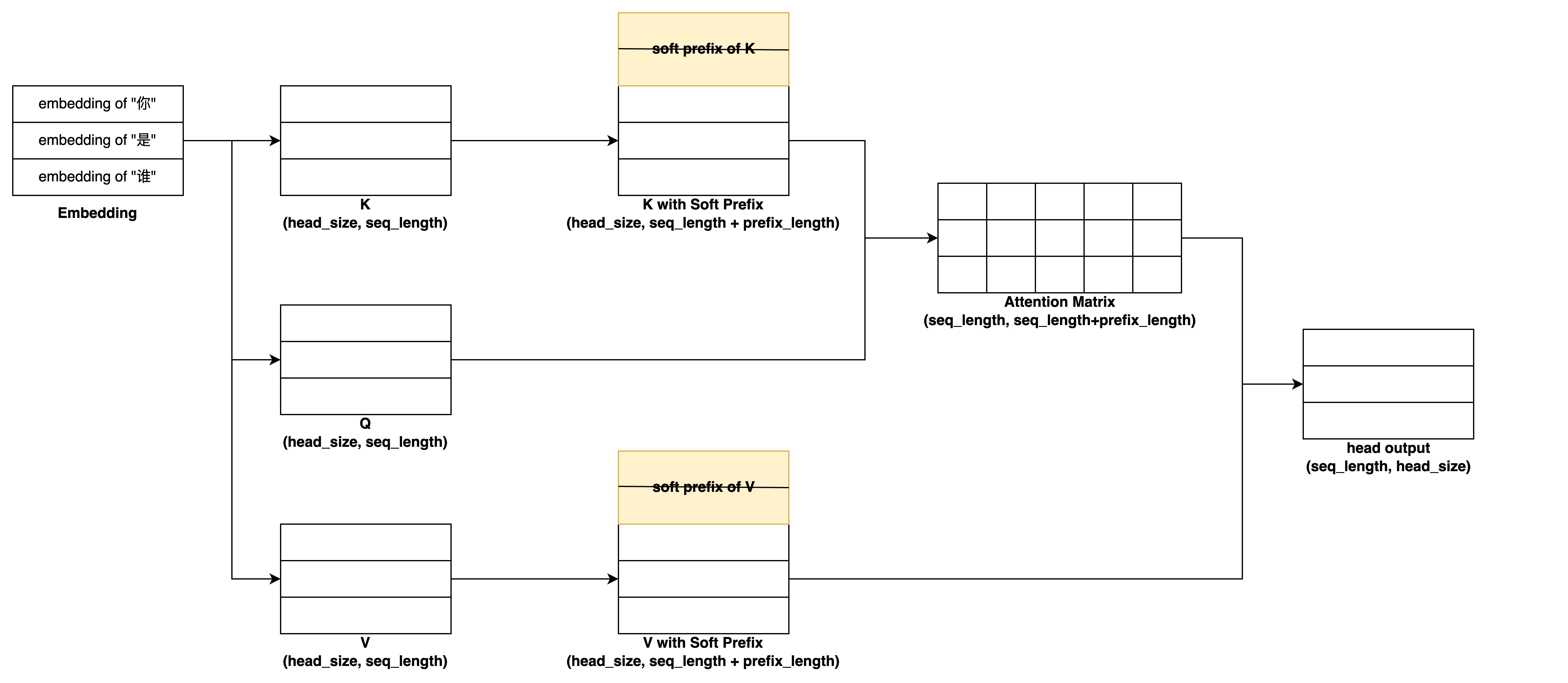
Prefix Tuning也是一种Continuous Template,论文的实验中用在GPT-2和BERT等模型的NLG任务
本节需要了解:
- Prefix Tuning中,每层transformer层输入添加的prefix是如何生成的?
- 论文中Prefix Tuning可训练的参数量和模型整体相比如何?
- prefix和prompt有什么区别?
P-Tuning
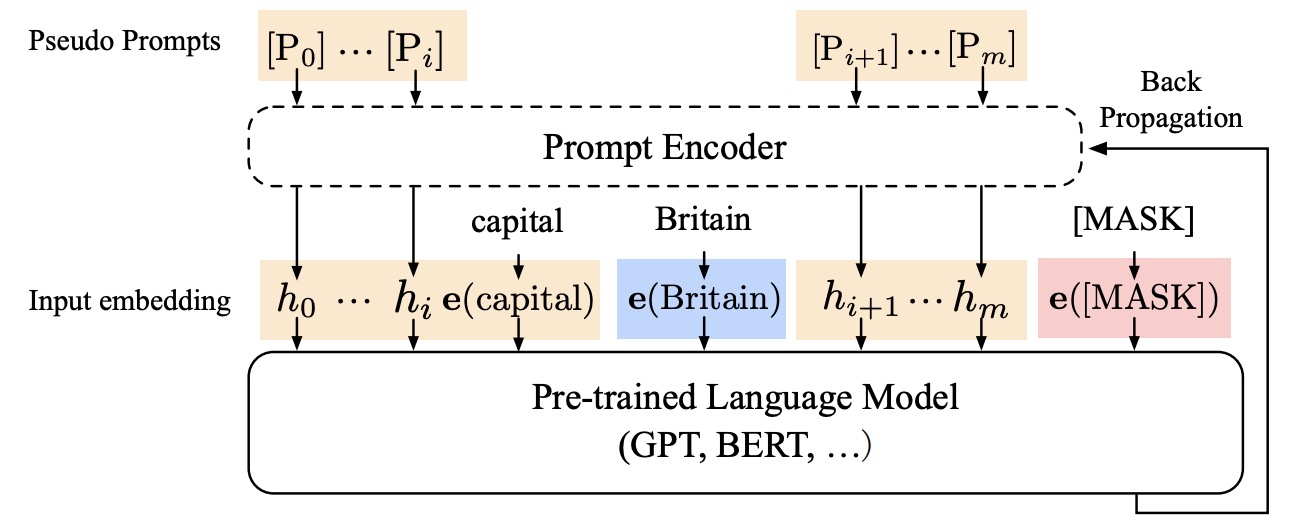
P-Tuning其实和Soft Prompt相似,通过给输入序列的Embedding前添加额外的Soft Prompt Embedding实现tuning,训练时冻结模型参数,只训练Soft Prompt Embedding参数。不过论文是通过一个小型的LSTM给出Soft Prompt Embedding,并且作者表示在训练SuperGLUE数据时甚至没有冻结预训练模型的参数,这一系列实验也确实证明Prompt Tuning这个思路是可行的。
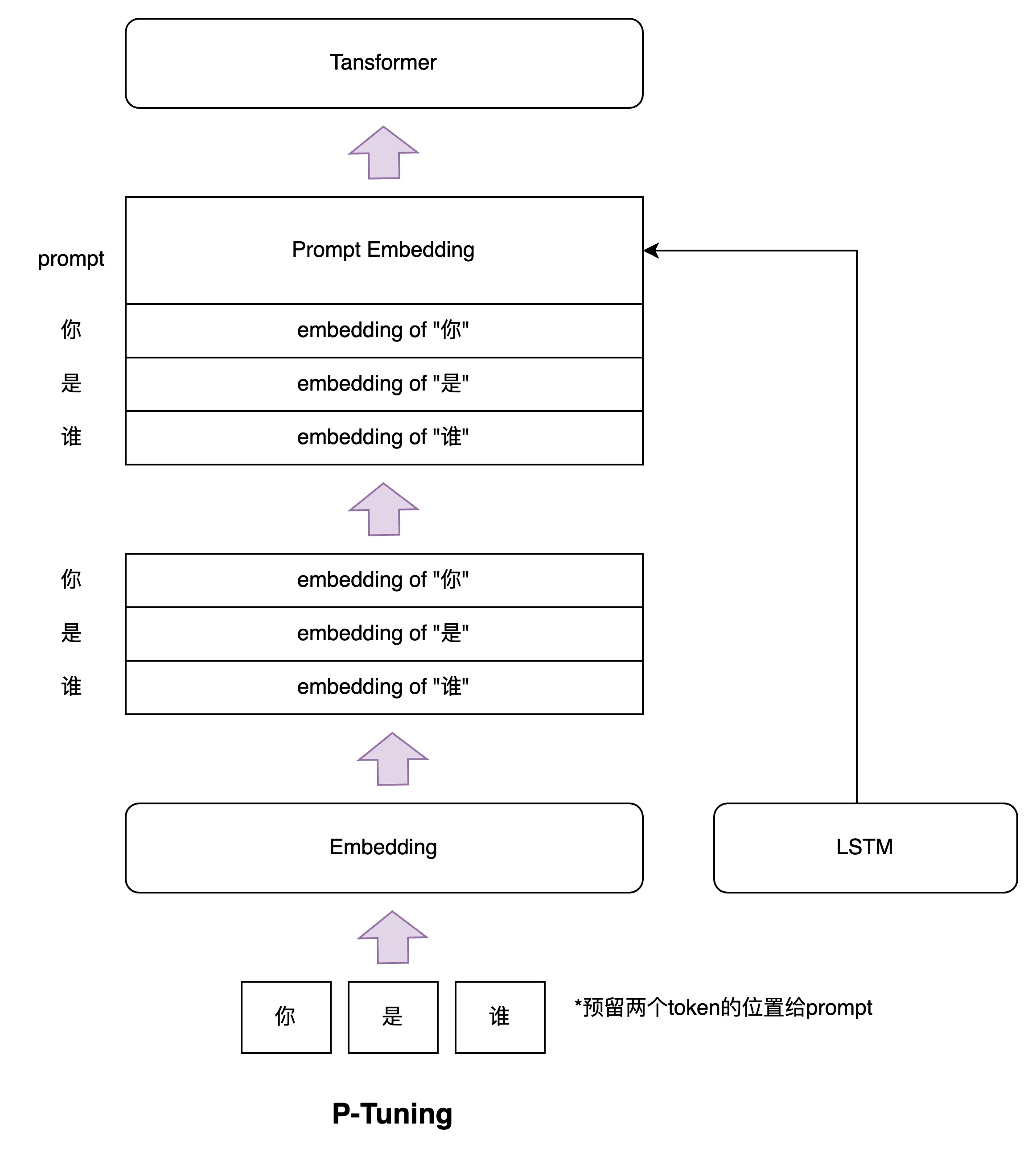
P-Tuning更加聚焦于NLU任务(这也是此前GPT一直不擅长的领域任务),借助P-Tuning,GPT首次在SuperGLUE上成绩超过了同等级别的BERT模型,颠覆了一直以来“GPT不擅长NLU”的结论,这也是该论文的题目由来。
本节需要了解:
- P-Tuning中有哪些参数被训练的,这些参数是如何注入到模型中的?
- P-Tuning和Prefix Tuning有什么异同?
P-Tuning V2
P-Tuning V2和Prefix Tuning很相似(甚至Huggingface上的实现这俩都一样),通过给每个Transformer层添加一个Soft Prefix来精调,其原理和Prefix Tuning基本没有差异,不过论文中做了大量NLU任务实验,同时做了一些模型架构和训练上的改进:移除重参数化的编码器(比如Prefix Tuning的MLP和P-Tuning的LSTM),针对不同任务采用不同Prefix长度,引入Prompt预训练+下游适配,分类任务回归传统分类标签范式
本节需要了解:
- P-Tuning V2和Prefix Tuning有什么不同?
- P-Tuning V2和P-Tuning有什么不同?
ICL

ICL作为PEFT方法,在$K$,$V$和非线性层后点乘一个可训练参数,精调时只训练这几个参数。不过该论文不止提出了一种PEFT方法,也提出了叫做T-Few的训练方法,这个可以自行了解了
一点小总结
对于上述的PEFT范式,这篇高分论文给了一个很好的全局视野,作者在不同的NLP领域任务上做实验对比不同PEFT方法的性能,并提出了一种Mix-And-Match Adapter的方法融合了Prefix Tuning和Scaled Parallel Adapter结构。我们在精调自己的LLM模型时,便可以结合自己的场景参考这篇论文选择合适的精调方式。
RLHF
RLHF也是InstructGPT精调时主要用到的方法,因此在介绍Instruction Tuning前,我们先看看RLHF的相关概念
本章引用的部分论文不需要完全阅读,因为后面Instruction Tuning会展开介绍
Reinforcement Learning
先简单介绍一下RL(Reinforcement Learning)
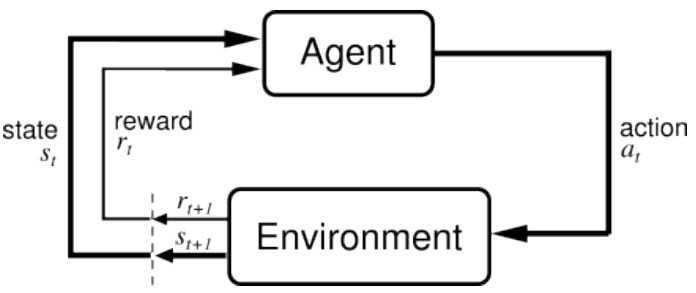
如图所示,被训练实体$Agent$从环境$Environment$收到$t$时刻动作$a_t$的反馈$r_t$和实体状态$s_t$后,对$t+1$时刻的环境采取行动$a_{t+1}$, $t+1$时刻的环境再次给予实体反馈$r_{t+1}$和实体的下一个状态$s_{t+1}$。符合这一范式的学习过程都可以称之为RL,比如马尔科夫决策过程就是一个RL过程,贪心算法也是一个RL过程。对于RL我们了解到这个程度即可,深入了解诶的话就涉及到很多和LLM无关的数学推导了
范式
我们再来看RLHF,RLHF(Reinforcement Learning from Human Feedback)就是用强化学习的方式依据人类反馈去优化语言模型
RLHF框架有三步:
- 预训练语言模型:选择自己的模型架构(Encoder?Decoder?激活函数?归一化层?),选择自己的预训练数据集,开启无监督训练
- 训练奖励模型RM(Reward Model):训练一个打分模型,这个模型接受一系列文本并返回一个人类偏好值,这个模型可以用与训练模型精调,也可以从头开始训练,架构自选,不过目前主流都认为RM应该和生成模型一样需要类似的文本理解能力
- 强化学习微调:利用Proximal Policy Optimization算法(后面一节详细展开)和RM对预训练语言模型的输出进行微调
| 这套框架也是符合RL范式的,我们基于训练数据集输入$Prompt$,从原始模型$\pi_{base}$和精调模型$\pi_{tuned}$中获得两段输出$\pi_{base}(y | x)$和$\pi_{rl}(y | x)$,然后利用奖励模型$RM$对两个结果进行打分得到分差$r_\theta(y | x)$(精调模型评分和原始模型评分分差自然是越大越好),然后用PPO算法来更新模型参数 |
当然整个流程也会有很多细节,比如分差也需要考虑大模型大幅偏离原始模型的问题,避免输出乱码的情况,接下来会对细节做梳理
Reward Model
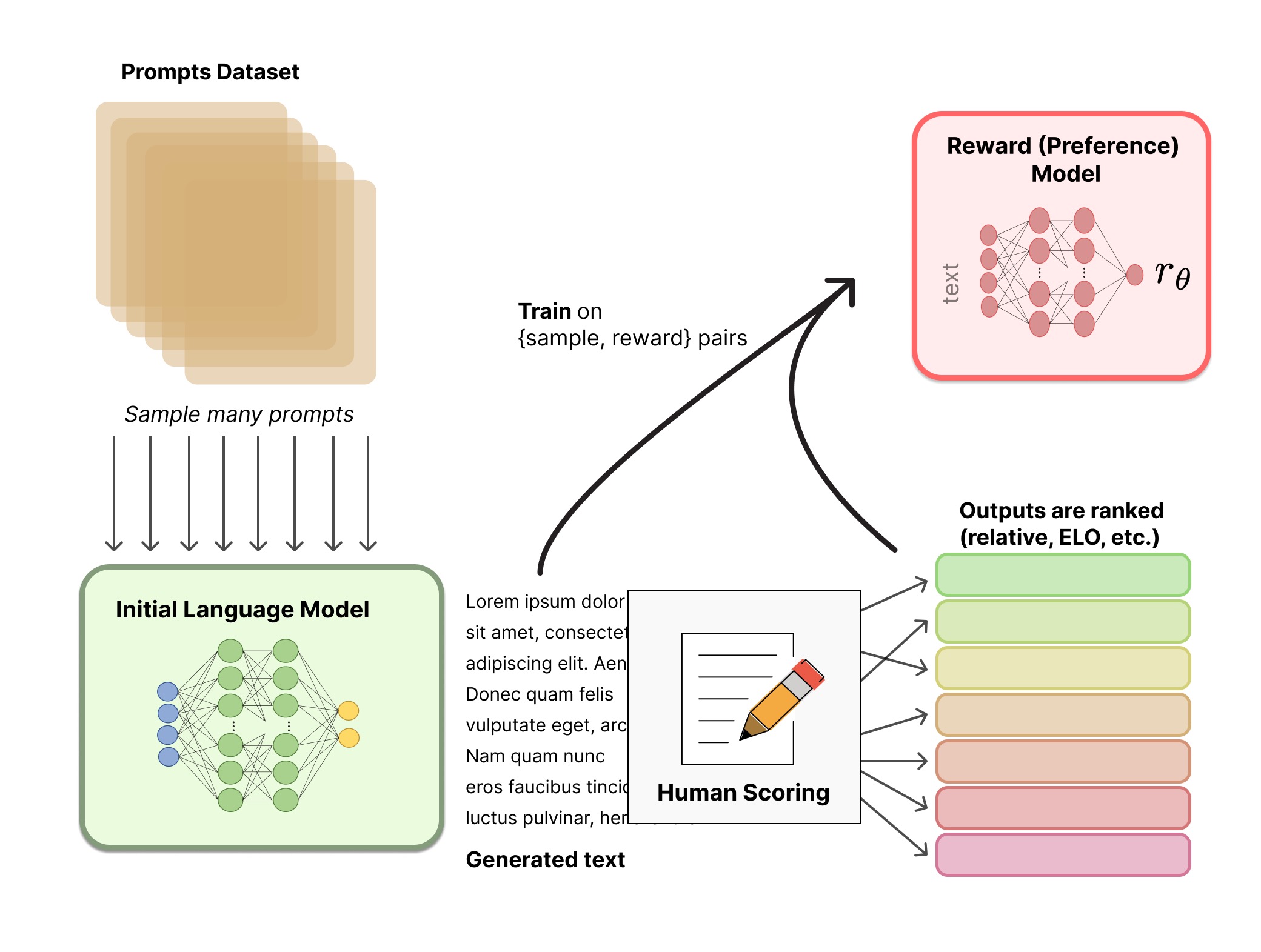
RM要干的事说简单点就是文本多分类器,把每一段文本都分类到某一个得分上,RM的训练是监督训练,训练数据喂给待精调模型,生成的数据人工打分从而得到训练集,其中得分排名的构建可以参考Elo或者人工构建,这里有开源的RM训练数据可以参考
对于RM的模型架构,论文中大多数用预训练好的大模型进行下游精调得到,因为模型也需要有语言理解能力来对文本进行解读。不过从论文中来看,RLHF系统的LM和RM未必需要大小相同:
- OpenAI使用了6B的RM微调175B的GPT-3
- DeepMind使用同一个70B的Chinchilla模型作为LM和RM
精调
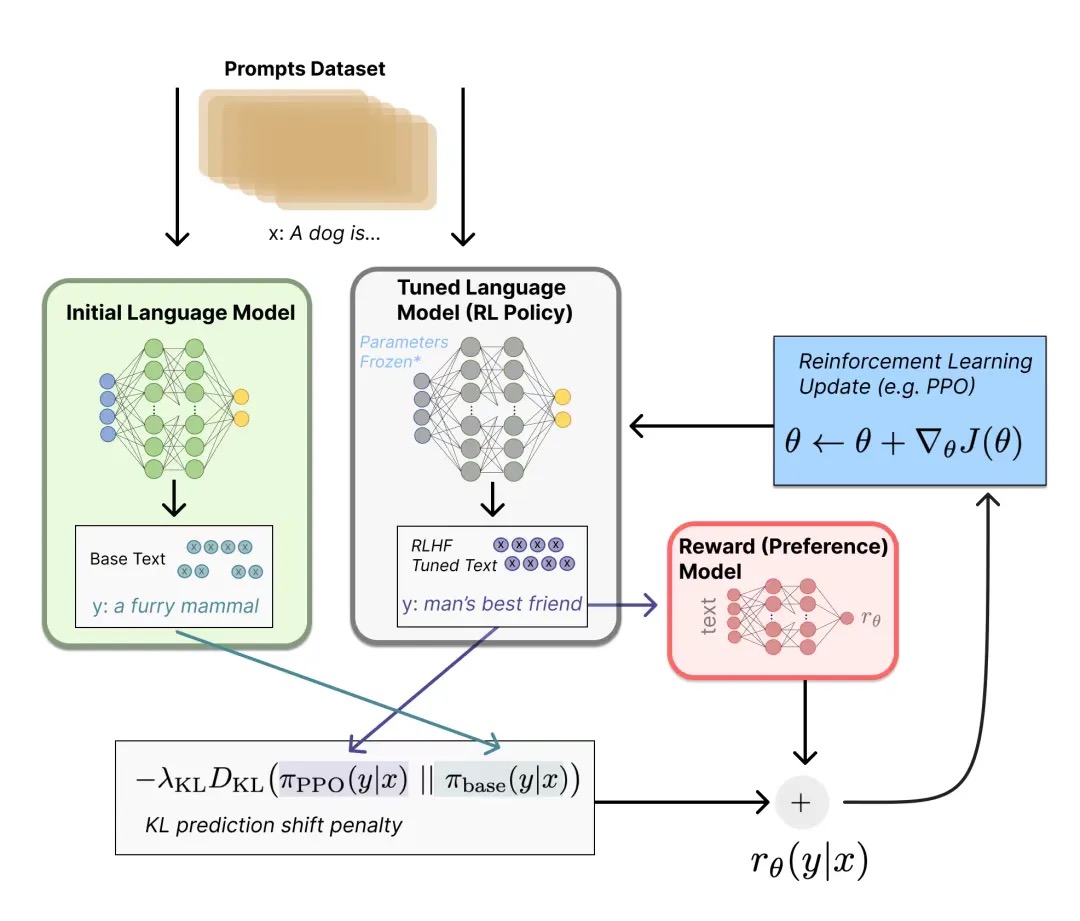
在获得了预训练大模型LM和RM后,接下来便是用训练集和RM来对LM进行精调
首先我们确定$Reward$的计算方法,对于两个模型$\pi_{base}$和$\pi_{tuned}$,我们能得到RM的打分差值$r_\theta’=r_{base}-r_{tuned}$,但是为了防止精调模型过于远离原始模型导致语序混乱,OpenAI和DeepMind都给公式添加了词分布序列的KL散度(KL散度可以自行搜索了)作为惩罚,使得最终的$Reward$为$r_\theta=r_\theta’-\lambda r_{KL}$
获得了$r_\theta$后,我们再用RL的优化算法针对精调模型进行参数更新$\theta+\nabla_{\theta}J(\theta)$,不同的RLHF论文也会使用不同的优化算法(大多论文用的是PPO算法),这个也可以自行阅读论文了解不同算法在不同模型上的差异性,具体算法的原理由于涉及太多太多数学公式推导,这里就不展开了,感兴趣的可以自行在这里查看
Instruction Tuning
和PEFT以及Prompt Tuning不同,Instruction Tuning的目的是激发语言模型的理解能力而不是补全能力。Instruction Tuning并不会冻结模型,它针对每个任务都生成instruction(可以理解为Hard Prompt),并在若干个full-shot任务上进行微调,最后在具体的任务上进行评估zero-shot泛化能力
Instruction Tuning其实主要是训练数据集的范式,原理上都不难理解,我们学习时其实更加需要关注不同方法的评估结果,要知道instructGPT就是靠Instruction Tuning训练出来的
FLAN
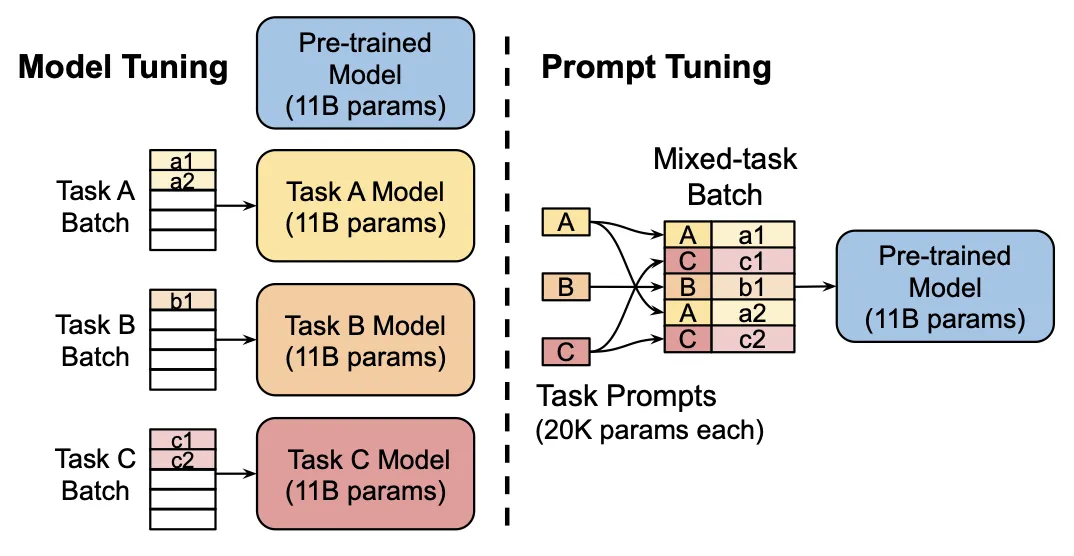
这篇论文首次提到Instruction Tuning的概念,并提出一种叫FLAN的tuning方法——一种通过提升语言模型对instructions的理解能力从而提高语言模型zero-shot学习能力的方法,该方法在大部分场景下对比GPT-3 175B的one-shot和few-shot都有明显的优势。Instruction Tuning和Fine Tuning、Prompt Tuning的区别如下图所示:
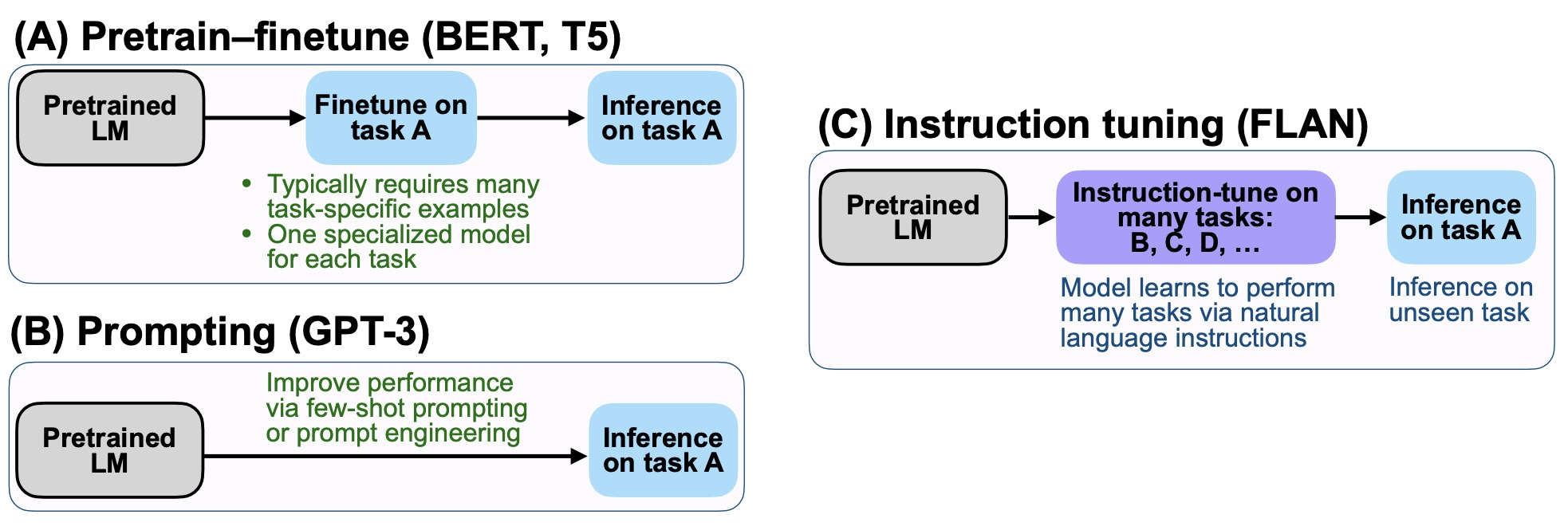
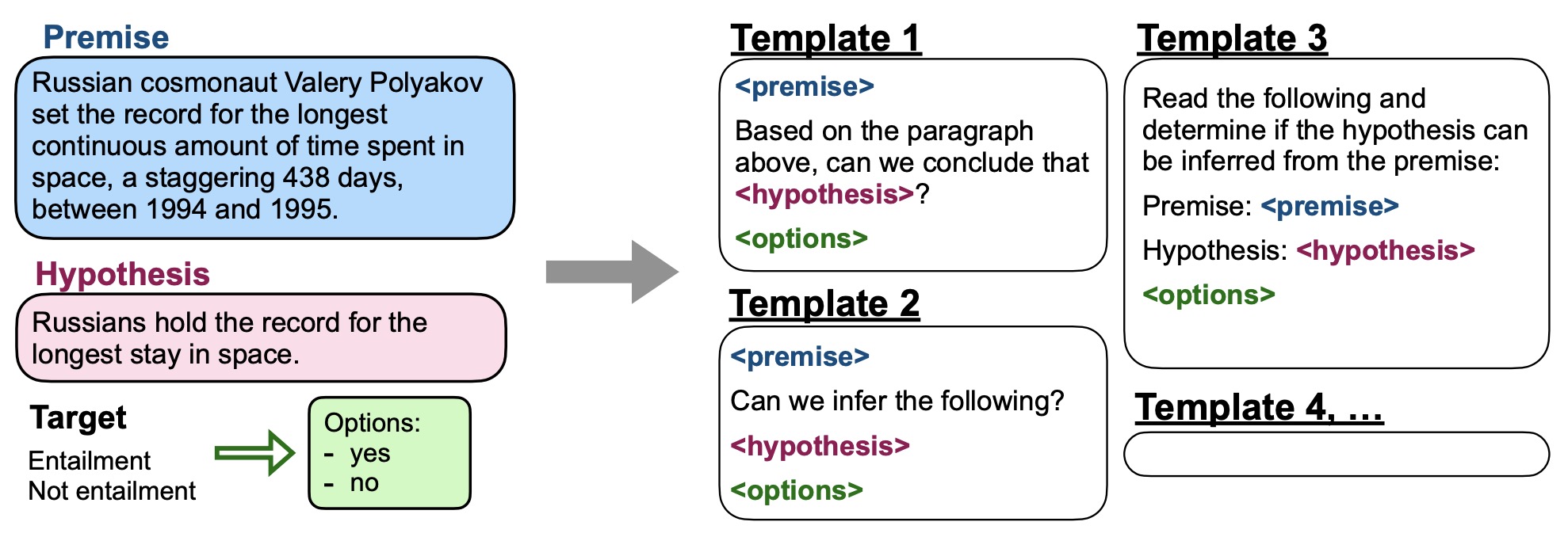
Instruction Tuning会针对NLU和NLG的数据集构建任务,每条数据都会人工构建10个模板填入形成新的数据集,评估某个任务时,会把属于该任务的所有数据从训练集中剔除并基于137B LaMDA-PT训练模型。最终25个训练集中的20个上,FLAN都超过了zero-shot的175B GPT-3
本节需要了解:
- FLAN的tuning方法
T0
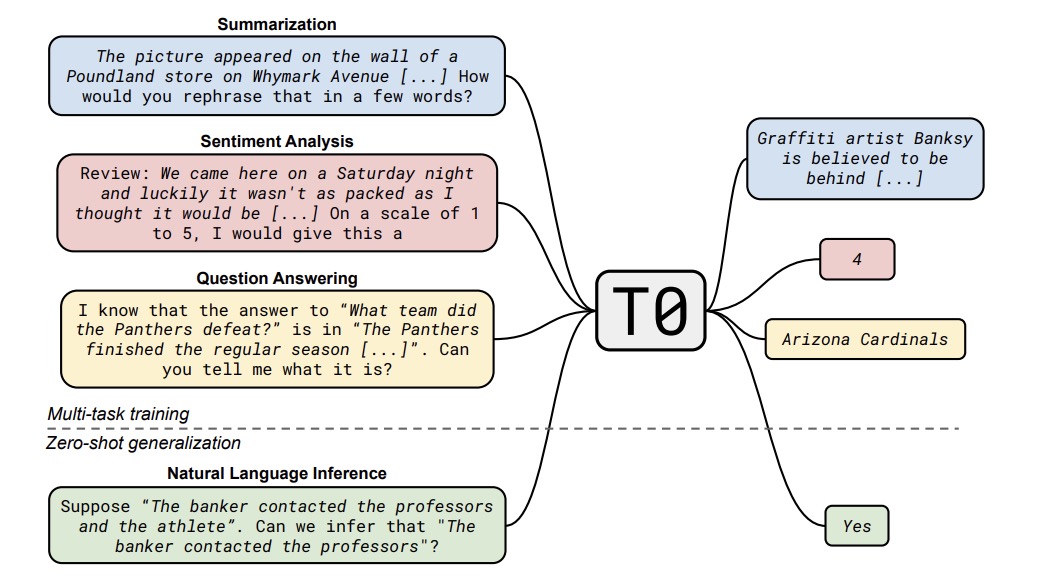
T0其实理解起来也很简单,相较于FLAN,T0使用了一个更小的11B encoder+decoder T5模型,针对171个多任务数据集创建了1939个精致的prompt,这些prompt都开源了,这些数据全部提供给模型训练,有且只训练一个模型以证明多任务学习能提升模型泛化能力。结果来看,T0模型用1/160的参数量在8/11个评估任务中超越了GPT-3
本节需要了解:
- T0的tuning方法?和FLAN有什么不同?
InstructGPT
该文章就是InstructGPT的论文,文章作者提出了一套基于RLHF的训练Instruction Tuning方法:1. 通过语言学家生成的数据集对待训练模型精调;2. 对多个prompt下的模型输出打分得到打分数据集,然后根据打分数据集训练Reward Model;3. 构建一个新Prompt,并通过上一步训练的Reward Model给待训练的模型进行RLHF
其中InstructGPT的RLHF优化算法使用一种叫PPO-ptx的新算法,它将预训练模型的梯度混合进PPO的梯度(具体的公式可以查看论文中的公式2),并得到了更好的效果
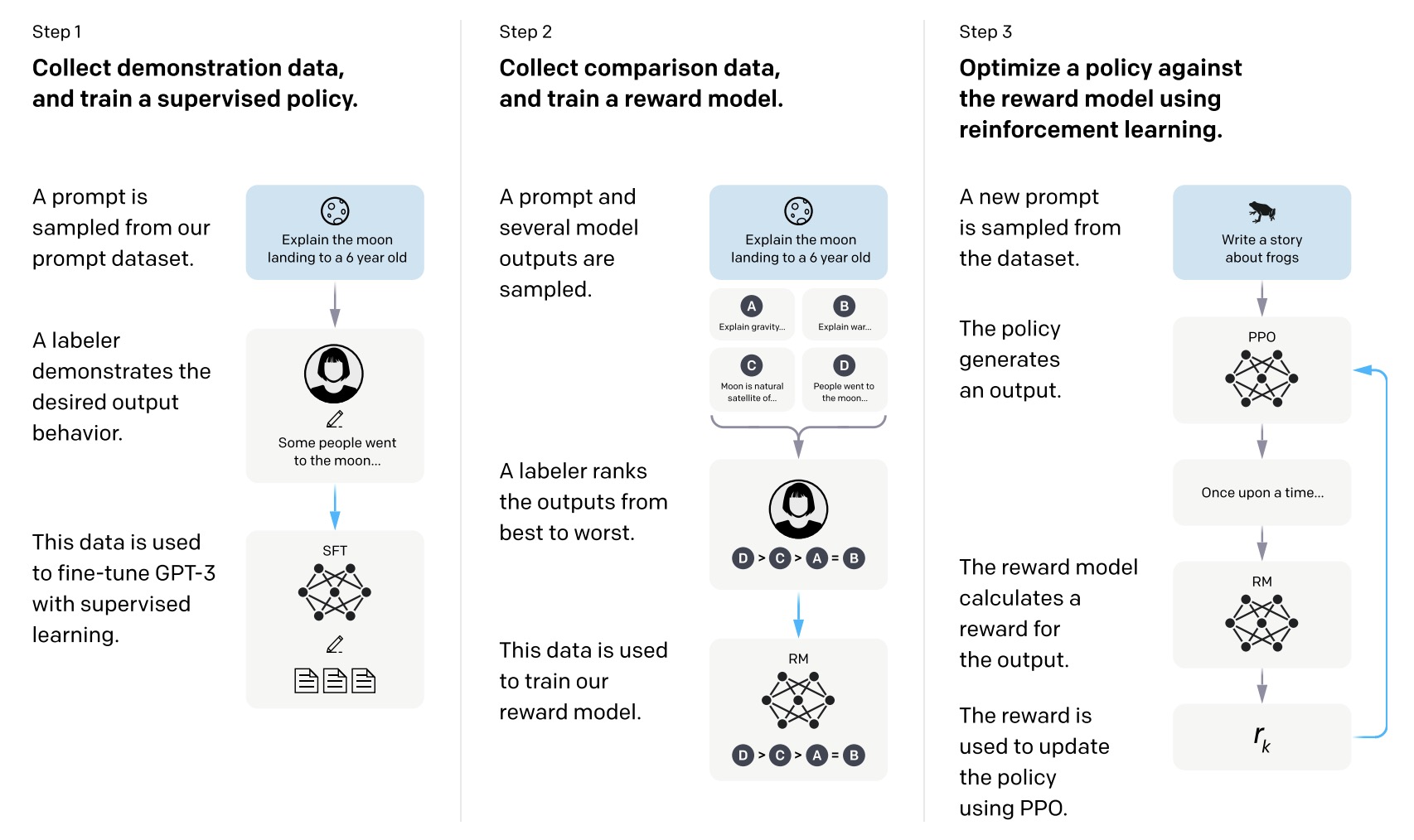
该论文的数据都是不开源的(OpenAI一贯风格),论文大量篇幅都集中评估和对比上,本身原理其实很好理解
本节需要了解:
- InstructGPT是如何训练的?
到此,你已经完整的了解了OpenAI截止InstructGPT的相关技术原理
写在结尾
想了想自己曾经也是个数学科班出身的算法工程师,咋就毕业从事云和PAAS行业了呢?不过云倒是一直和ai结合的紧密,写这篇文章的idea其实很早就有了,这次刚好借着大模型的热度一口气梳理完了,后续如果自己再因为什么原因忘了这块算法的知识也能看着复习了hhhhhh
那么,到此为止这篇文章到这里就介绍完了GPT-3和InstructGPT了,其实还有很多可以单独起一个文章的算法我都没提到(比如RL的一系列优化算法),由于这些涉及了太多的数学推导而且篇幅过长,我后续再考虑整理一下,文章内也可能有遗漏和错误的地方,如果有的话也希望各位读者有功夫指正一下~
References
[1] https://github.com/thunlp/PromptPapers
[2] https://zhuanlan.zhihu.com/p/558286175
[3] https://nooverfit.com/wp/15-%E5%A2%9E%E5%BC%BA%E5%AD%A6%E4%B9%A0101-%E9%97%AA%E7%94%B5%E5%85%A5%E9%97%A8-reinforcement-learning/
[4] https://huggingface.co/blog/zh/rlhf